The IberSPEECH 2020 Challenge starts!
Zaragoza, March 1, 2020
ALBAYZÍN EVALUATIONS
IBERSPEECH-RTVE 2022 CHALLENGE RESULTS
DATASETS
RTVE Databases License
- The RTVE data is available subject to the terms of a licence agreement with the RTVE.
To download the RTVE databases, a representative of your research group, company,..., must sign the license agreement (Digital signature is valid)
Please contant the challenge organizers
SYSTEM DESCRIPTIONS
-
Haritz Arzelus, Iván G. Torres, Juan Manuel Martín-Doñas, Ander González-Docasal and Aitor Alvarez
The Vicomtech-UPM Speech Transcription Systems for the Albayzín-RTVE 2022 Speech to Text Transcription Challenge
-
Fernando López and Jordi Luque
TID Spanish ASR system for the Albayzin 2022 Speech-to-Text Transcription
-
Martin Kocour, Jahnavi Umesh, Martin Karafiat, Ján Švec, Fernando López, Jordi Luque, Karel Beneš, Mireia Diez, Igor Szoke, Karel Veselý, Lukáš Burget and Jan Černocký
BCN2BRNO: ASR System Fusion for Albayzin 2022 Speech to Text Challenge
-
Antonio Miguel, Alfonso Ortega and Eduardo Lleida
ViVoLAB System Description for the S2TC IberSPEECH-RTVE 2022 challenge
-
Hervé Bredin
pyannote.audio speaker diarization pipeline at Albayzin 2022
-
Roman Shrestha, Cornelius Glackin, Julie Wall and Nigel Cannings
Intelligent Voice Speaker Recognition and Diarization System for IberSpeech 2022 Albayzin Evaluations Speaker Diarization and Identity Assignment Challenge
-
Germán Bordel, Luis Javier Rodriguez-Fuentes, Mikel Peñagarikano and Amparo Varona
GTTS Systems for the Albayzin 2022 Text and Speech Alignment Challeng
Speech to Text Challenge
Speaker Diarization
Text and Speech Alignment Challenge
CHALLENGE RESULTS PRESENTATION
-
Eduardo Lleida
ALBAYZÍN EVALUATIONS: IBERSPEECH-RTVE 2022 CHALLENGE RESULTS
SPEECH to TEXT CHALLENGE (S2TC)


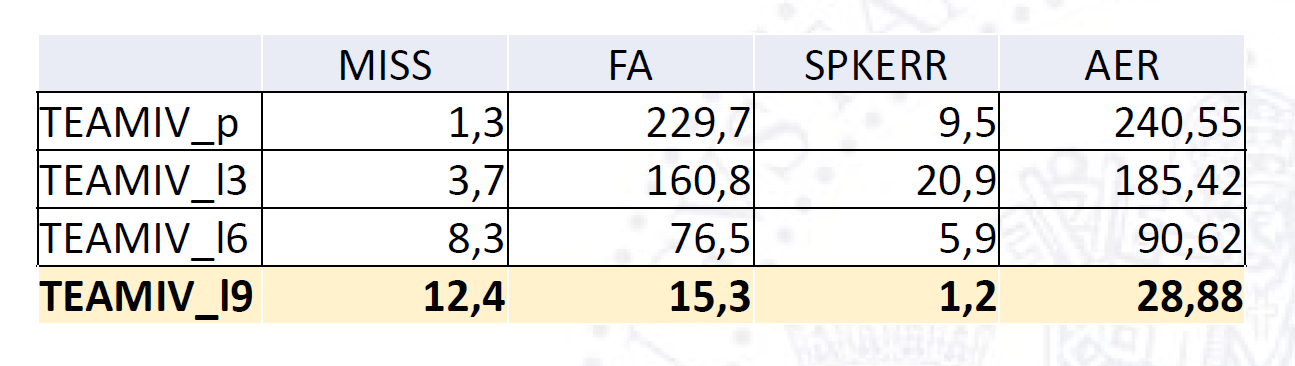
SPEAKER DIARIZATION and IDENTITY ASIGNEMENT(SDIAC)
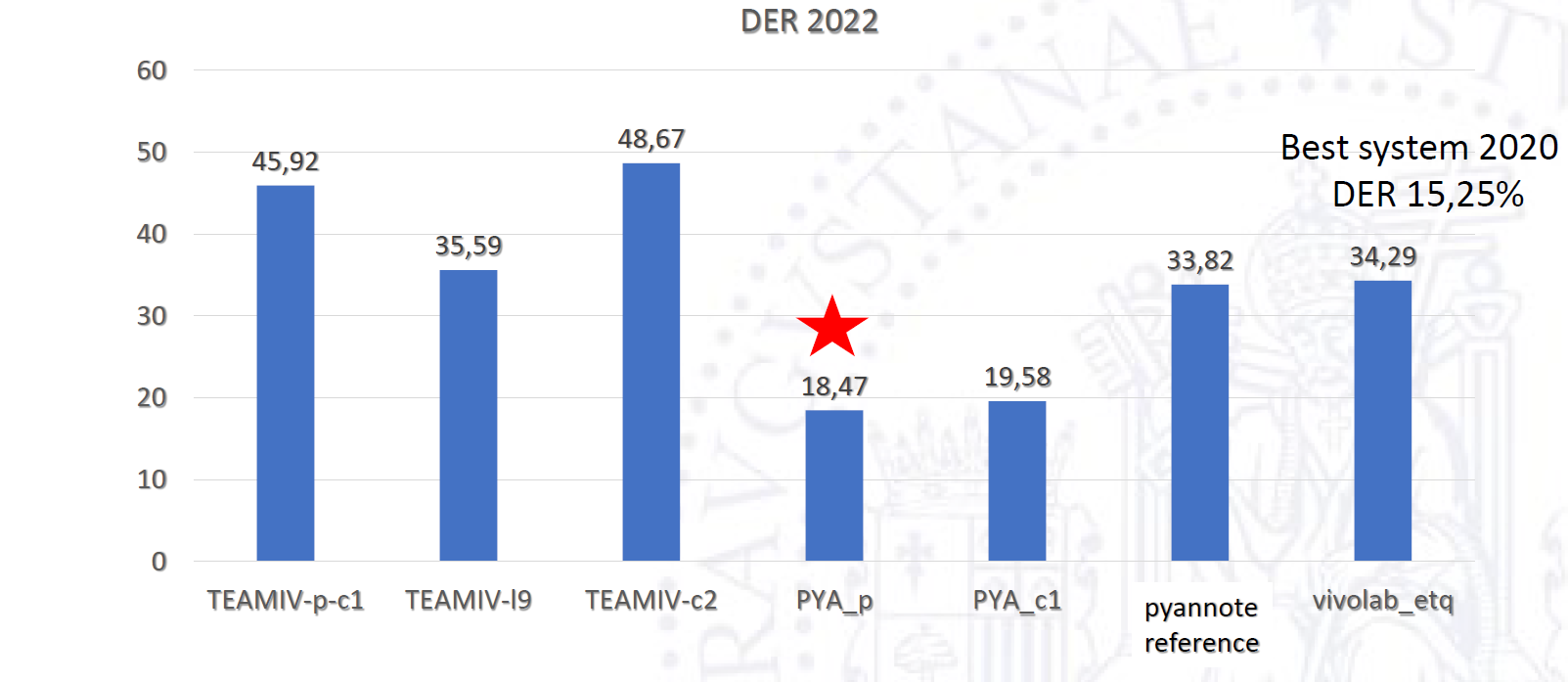
SPEAKER DIARIZATION
SPEAKER DIARIZATION and IDENTITY ASIGNEMENT